Image-Editing-using-GAN
Developing an image editing application to edit images to have a desired attribute using Generative Adversarial Networks(DCGAN and CycleGAN)
Image Editing using GAN
“I wonder how I would have looked in this picture if I had a hat on…”, “If only I were smiling in this one…” Going through our phone galleries, we have all had similar thoughts every now and then. But you can’t change a clicked picture, right?

Figure 1: Wondering how the place would look in winters?
Yes we all have been clicking a lot of photographs, and though there’s a plethora of features available in today’s image editing applications, it is time to imagine what the ‘next generation of image editing tools’ would be like. These new tools would allow users to edit an image to have a desired attribute or feature such as ‘add a hat’ or ‘change hair color’, to create new images.
To make this possible, we need an algorithm which can learn different features of an image, edit them as required and then generate a new image. Generative Adversarial Networks or GANs developed by Ian Goodfellow [1] do a pretty good job of generating new images and have been used to develop such a next generation image editing tool.
GANs, a class of deep learning models, consist of a generator and a discriminator which are pitched against each other. The generator is tasked to produce images which are similar to the database while the discriminator tries to distinguish between the generated image and the real image from the database. This conflicting interplay eventually trains the GAN and fools the discriminator into thinking of the generated images as ones coming from the database. For a simplified tutorial on GANs refer this.
In this post, I would go through the process of using a GAN for the image editing task.
Pairing DCGAN with Encoder
Deep Convolutional Generative Adversarial Network (DCGAN) as proposed by Radford [2] uses strategies to better train GAN. In this work, I have implemented the DCGAN model for this task. I have used the CelebA Face Database [3] which has 200,000+ images of celebrities with over 40 labeled attributes such as smiling, wavy hair, moustache etc.
The generator of the DCGAN model takes in a vector of 100 dimensions, also known as z-vector and converts this into an image similar to the images present in the database. While training, the generator learns to represent this z-vector into a facial image accounting for all the attributes. Some of the generated images after sampling the generator are shown below. Follow this link for the DCGAN code.
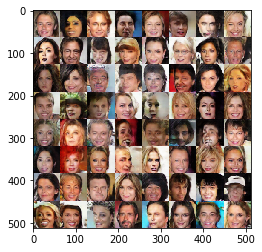
Figure 2: Generated Samples after 6th epoch of training
DCGAN model is an unconditional model i.e. the image attributes aren’t used to train it rather the attributes are used to manipulate images using an encoder-generator pair.
As the name says, an encoder is used to encode an image to a small representation. In this case, it converts an image to a z-vector of 100 dimensions which is taken as an input by the generator of DCGAN model so that the generator produces an image similar to the encoder input.
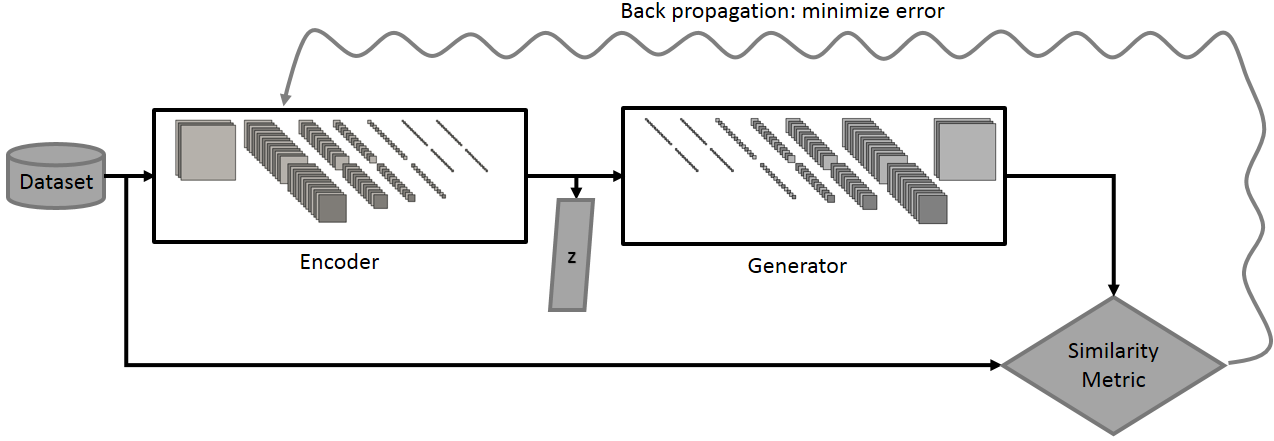
Figure 3: Encoder Training Source
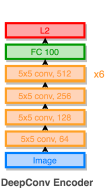
Figure 4: DeepConv Encoder Source
I have used the DeepConv Encoder model as proposed in this paper. Some of the generated samples of this encoder-generator pair are listed below. For the implementation of the encoder model, follow this link.
| Input Image | Output Image |
|---|---|
 |
 |
 |
 |
Figure 5: Encoder-Generator Samples
The z-vector has an interesting property; it can be easily manipulated using arithmetic operations allowing for manipulation of images to create new images.
Image Editing Pipeline
The encoder produces an encoding or a z-vector of the input image. This latent representation (z-vector) is manipulated with the representation of some desired attribute. The ‘edited’ z-vector is then passed as input to the generator, which produces an image similar to the input image but having the desired attribute.
To find the representation of different attributes, all database images are passed through the encoder. The average encoding of all the images which don’t have a particular attribute is then subtracted from the average encoding of the ones which do. For example – To compute the representation of ‘smiling’, all images are first encoded. Now, let the average encoding of images having the attribute ‘smiling’ be ‘s’ and the average encoding of all images not having that attribute be ‘ns’. Then the z-vector for smiling becomes, z = s – ns.
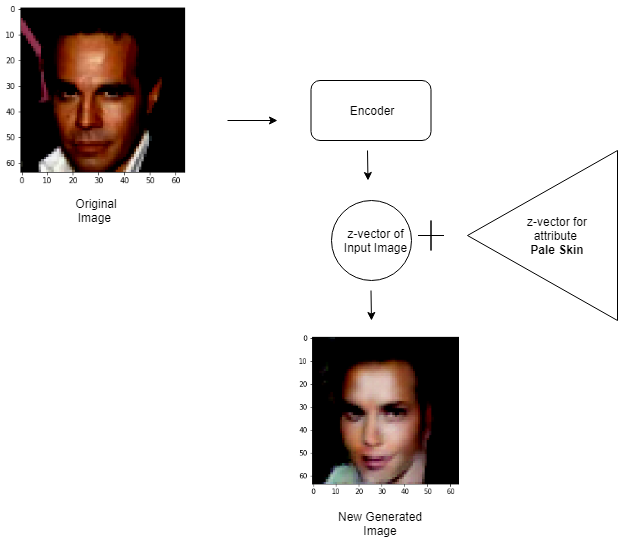
Figure 6: Adding Attribute ‘Pale Skin’
| Orignal Image | Encoded Image | Smiling | Bushy Eyebrows | Mustache | Wavy Hair |
|---|---|---|---|---|---|
 |
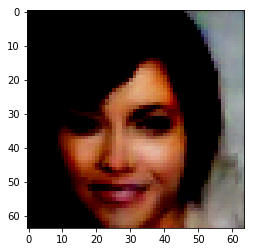 |
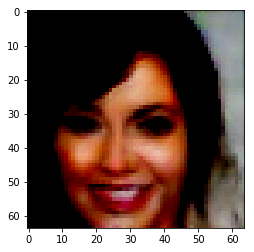 |
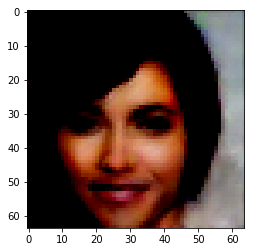 |
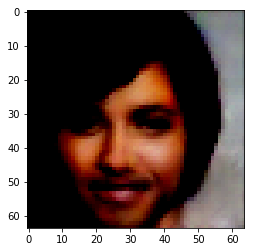 |
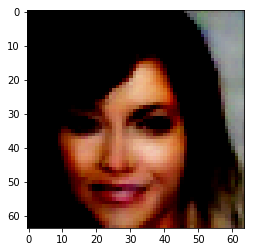 |
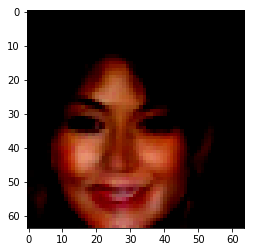
| Orignal Image | Encoded Image | Male | High Cheekbones | Blond Hair | Bangs |
|---|---|---|---|---|---|
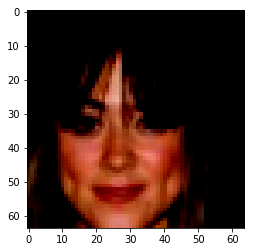 |
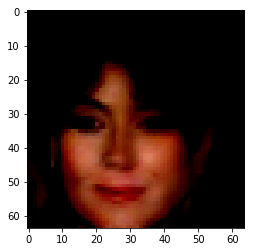 |
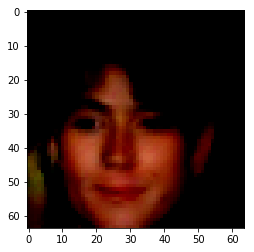 |
 |
 |
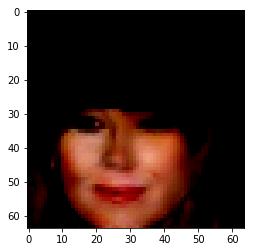 |
Figure 7: Manipulation Samples
CycleGAN
Cycle Consistent Generative Adversarial Networks (CycleGANs) [4] were developed to solve the problem of unpaired image-to-image translation, mapping images from one domain to the other domain in an unsupervised manner.
The CycleGAN model is made up of two GANs which train in a fashion similar to that of DCGAN, but they use an extra ‘cyclic loss’ term to account for the cycle consistency between the input image and the generated sample.
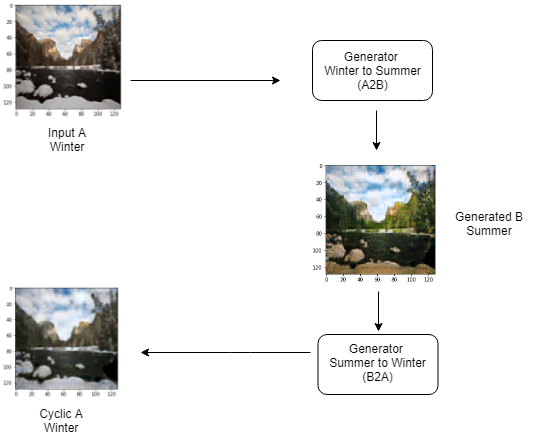
Figure 8: CycleGAN working
Image from one domain is passed to the model which converts this to an image of the other domain. This generated sample is then converted back to the first domain to maintain the cyclic nature. My implementation the CycleGAN model is available here. For a tutorial on CycleGAN refer this. Below are some samples generated usin CycleGAN.
Training CycleGAN on Summer-Winter Yosemite Database
| Input Image | Output Image |
|---|---|
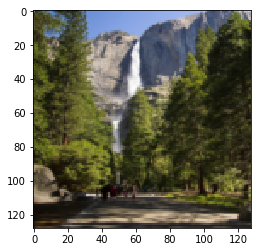 |
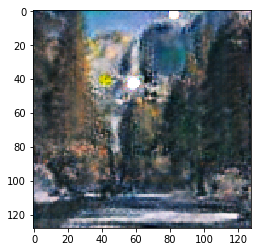 |
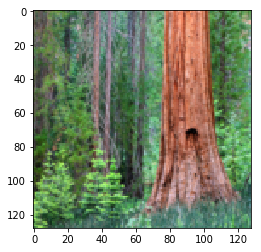 |
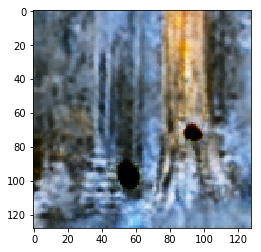 |
Figure 9.1: Summer to Winter Yosemtie
| Input Image | Output Image |
|---|---|
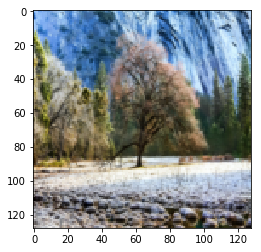 |
 |
 |
 |
Figure 9.2: Winter to Summer Yosemtie
Training CycleGAN on Photo-Monet Paintings Database
| Input Image | Output Image |
|---|---|
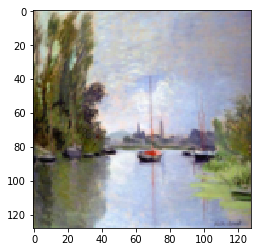 |
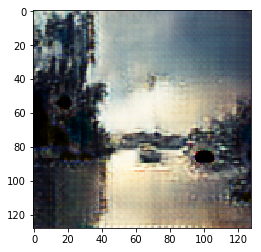 |
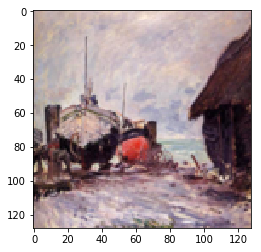 |
 |
Figure 10.1: Monet Paintings to Photo
| Input Image | Output Image |
|---|---|
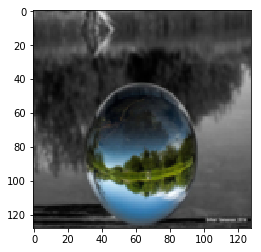 |
 |
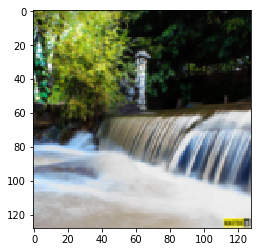 |
 |
Figure 10.2: Photo to Monet Paintings
Thanks for reading.
References
- Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in neural information processing systems. 2014.
- Radford, Alec, Luke Metz, and Soumith Chintala. “Unsupervised representation learning with deep convolutional generative adversarial networks.” arXiv preprint arXiv:1511.06434 (2015).
- Guo, Yandong, et al. “Ms-celeb-1m: A dataset and benchmark for large-scale face recognition.” European Conference on Computer Vision. Springer, Cham, 2016.
- Zhu, Jun-Yan, et al. “Unpaired image-to-image translation using cycle-consistent adversarial networks.” arXiv preprint arXiv:1703.10593 (2017).